During the Christmas break, I indulged in some aimless dialogue with Dall E 2 and Midjourney, two of the most popular and impressive deep-learning generators of images based on text prompt. Demos of both systems are freely accessible.
The prompts I used are mostly about cartography and maps, but also entirely random and silly stuff (e.g., Cthulhu at the British Parliament as a subtle political metaphor). You can see the results below, ranging from the hideous to the beautiful (at least to my non-trained eye). The prompts are visible in the file names. Some thoughts below.
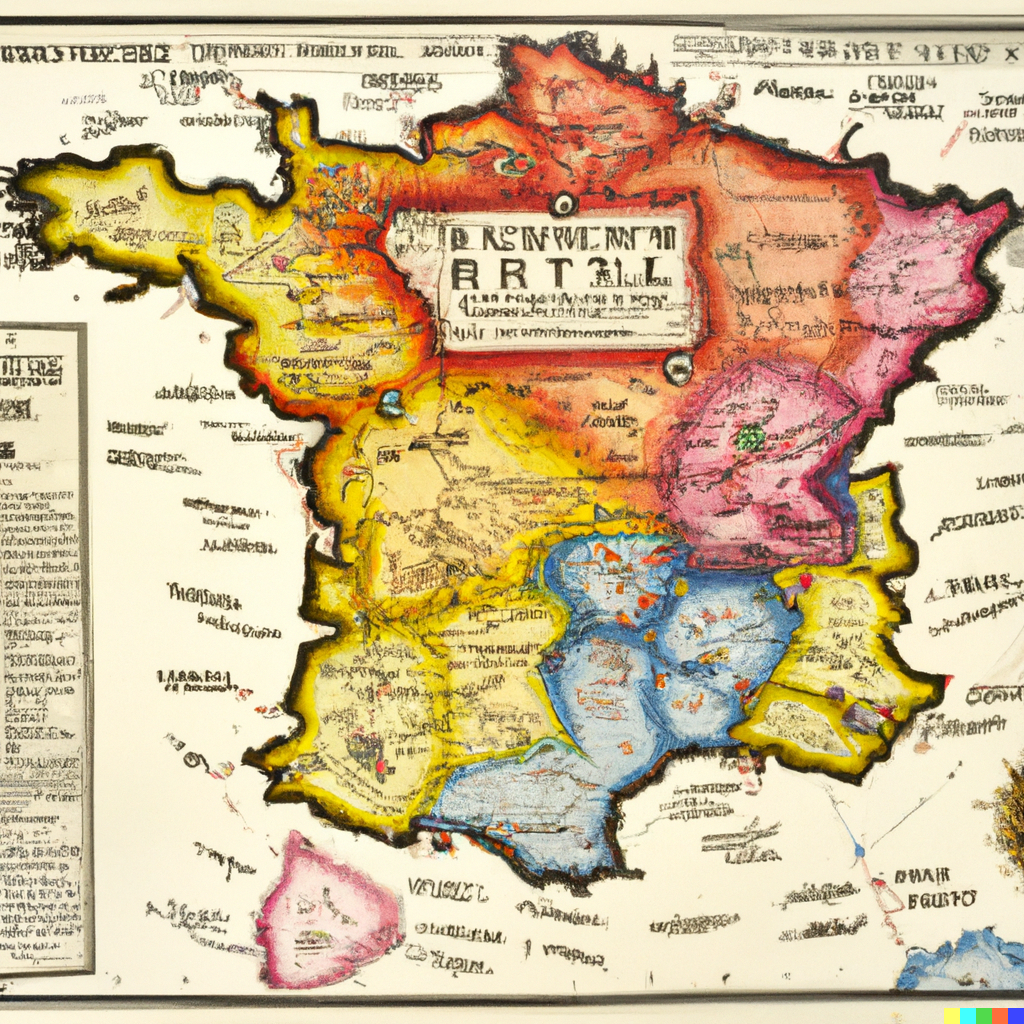
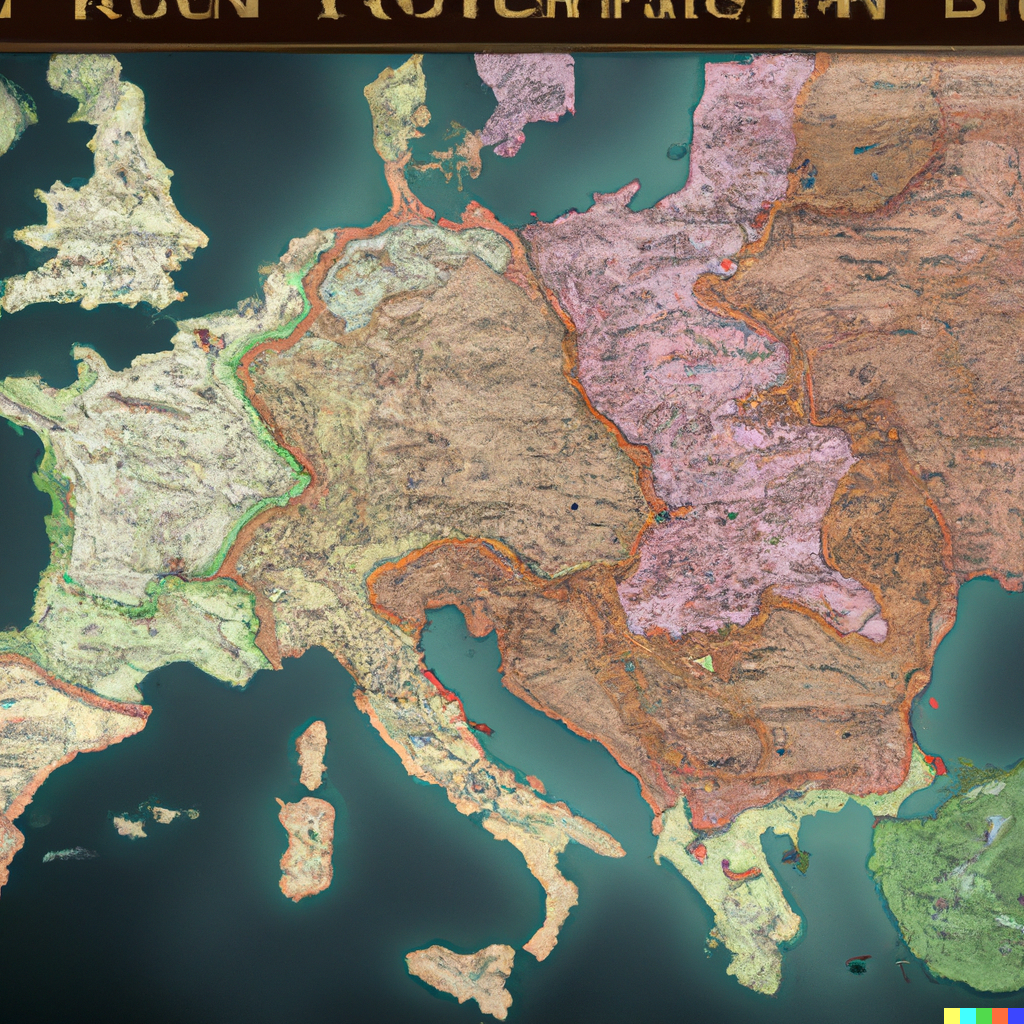
Dall E 2 results







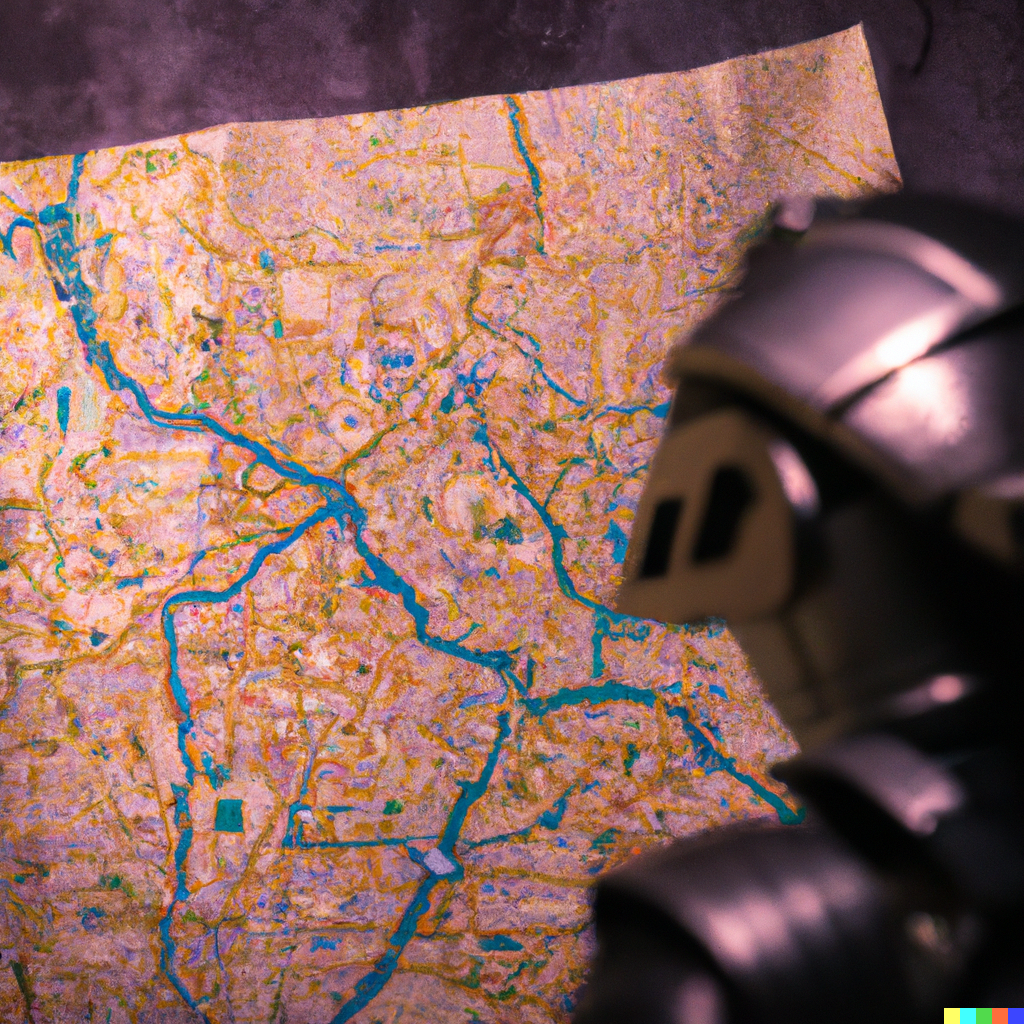


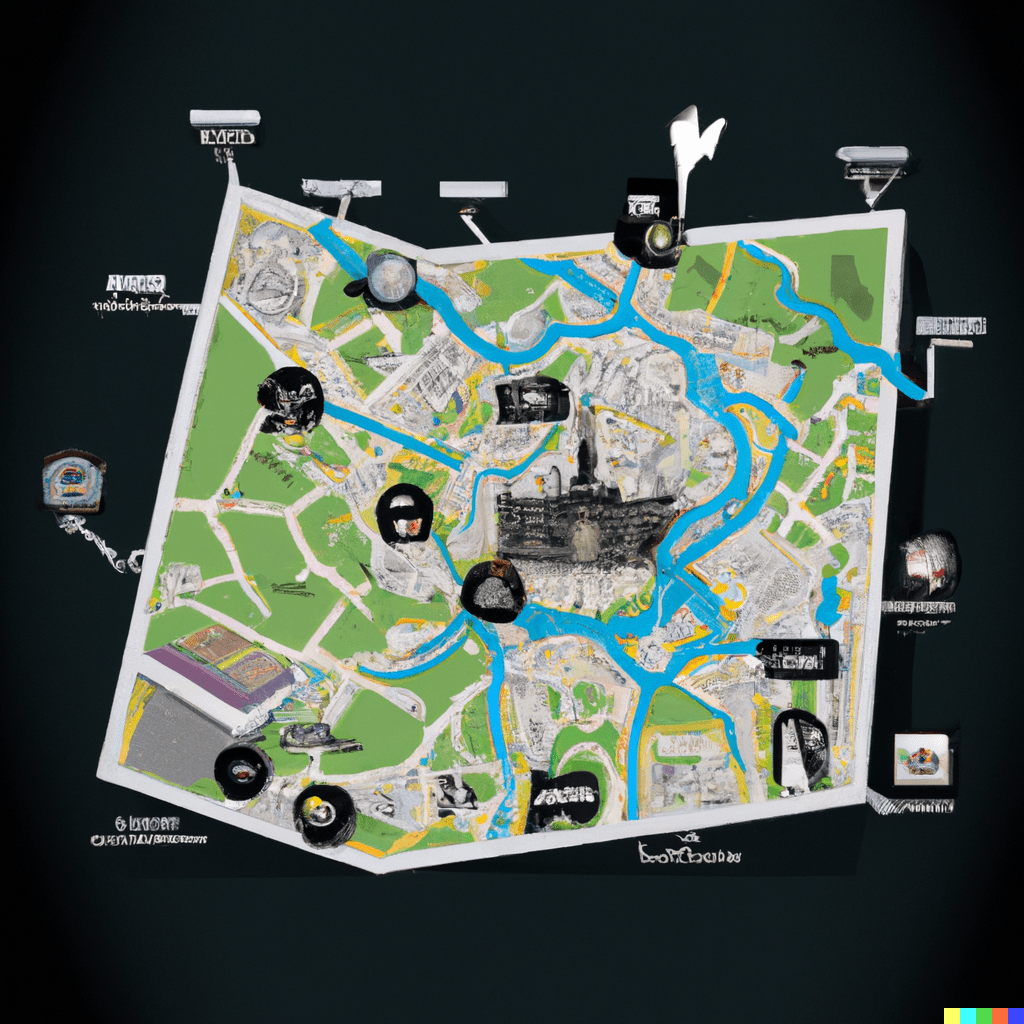

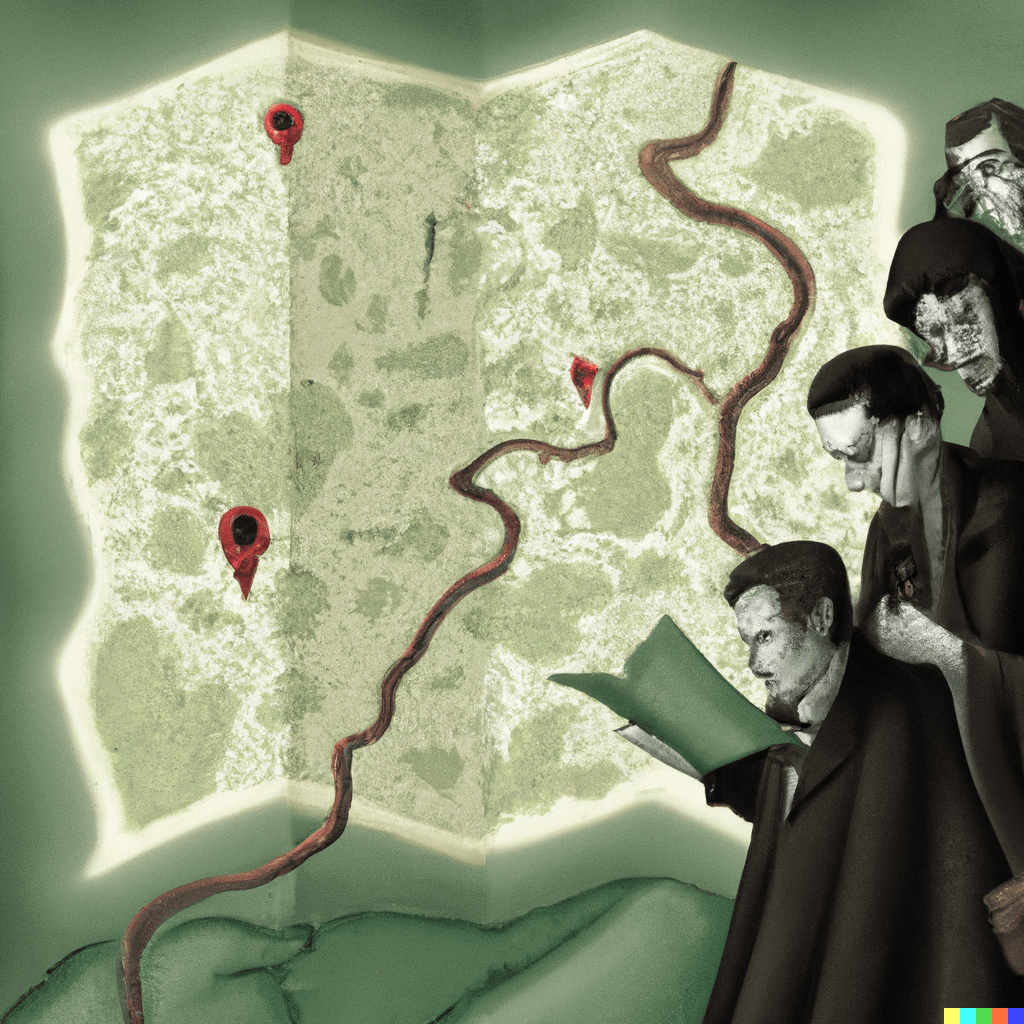













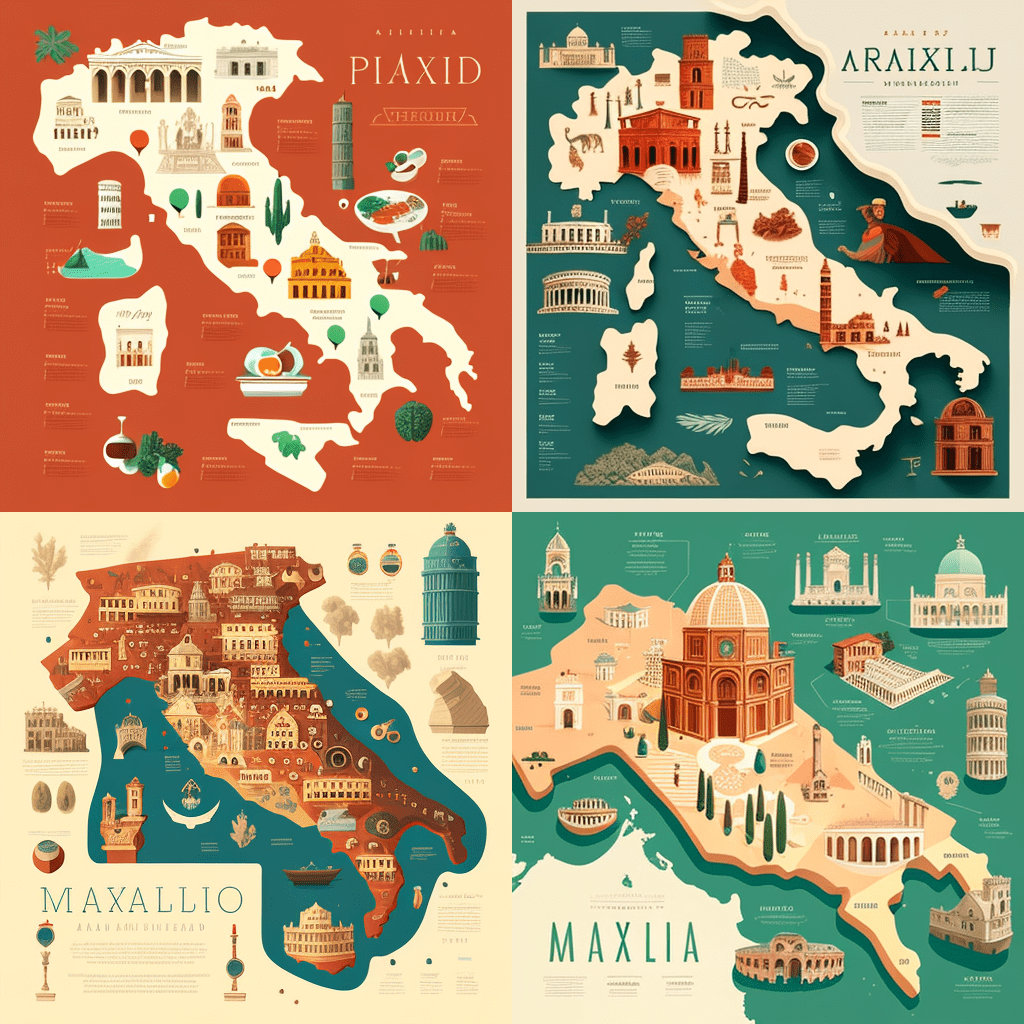
Midjourney results





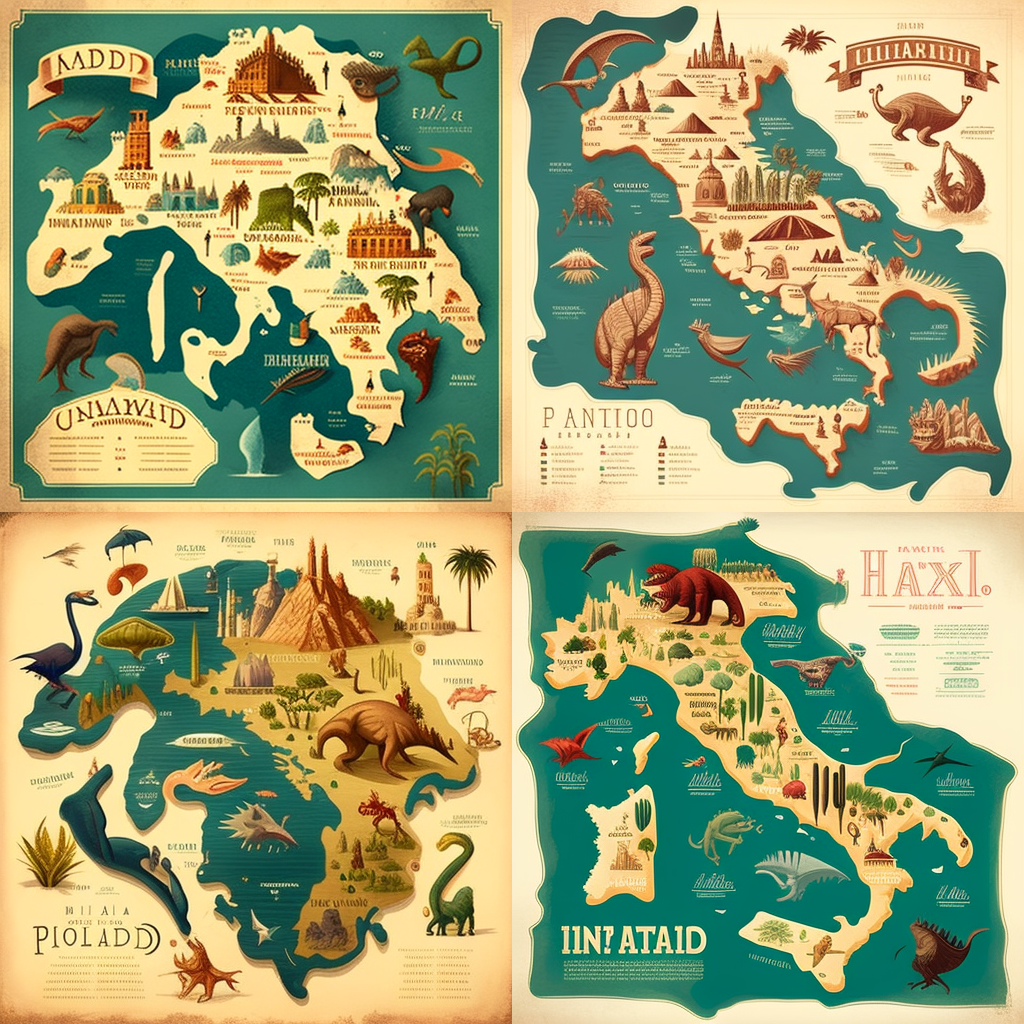




Some impressions
- These systems are truly awe-inspiring. I’ve always been quite sceptical of bombastic AI claims (see one of my papers on this very topic), but these generators mark a turning point in the ability of systems to synthesise novel information from vast troves of historical data, with deep implications for, well, any activity that requires generating text, code, images, and music.
- While a good artist / graphic designer can still easily outperform image-generating systems, the idea that a fully automated system can generate meaningful, interpretable images on virtually any topic, based on some minimal prompt, is remarkable in itself. I guess I feel like the first non-experts who witnessed a computer programme play chess competently, not like a grand master but well enough to beat most amateurs. Jaw-dropping.
- The maps I’ve generated show an interesting tendency to distort geometries in an unpredictable, inconsistent way. The systems learn shapes from existing maps and generate similar ones that are still recognisable, but also different, like in a sort of counterfactual cartography. I particularly love the maps of Italy, in which both the country and the decorative objects are mangled, inconsistent, and malleable like perceptions in dreams. This is perhaps why many of these images feel like a cheap, run-of-the-mill imitation of surrealism.
- It’s fascinating how these tools generate map labels in a proto/meta script, merging actual symbols. Presumably, most maps in the training data are European and North American, although traces of other scripts emerge.
- The main flaws are artefacts that are clearly visible on human faces and hands. This somehow replicates the difficulty for art students to get faces and hands right. The artefacts are often less visible on other types of objects.
- Dall E generates more obvious artefacts than Midjourney, but its results are more, for lack of a better term, artistic. It’s as if Dall E is a better visual artist, but does not care enough about details, while Midjourney is a careful but dull graphic designer.
- What are the implications for scientific cartography? Currently, the systems appear more suitable as support tools for graphic design, stock image generation, visual arts, and the like. How could we use these systems to stimulate map design? I look forward to seeing examples of AI-generated map styles.
